Transformer - Attention is All you Need
泛读文章时候刷到了tramsformer框架的鼻祖:Attention is All you Need 1。于是静心花了一晚上读了读,有感而记。
为什么会对这篇文章感兴趣?因为我自己的文章中用了某种方式统一编码了方向梯度场,然后再解码得到每一个位置的运动方向,于是我把这种模式叫 ‘collaborative directional encoding-decoding strategy’,取代了传统的’Separate Strategy’。接下来就是,我收到了审稿人的comment:To be honest, the two key contributions are already very common design in the computerscience and pattern analysis community。恰好transformer是和encoding-decoding相关的,所以想读一读。
这篇文章仅用了attention的方法,颠覆性在于完全抛弃了应用于encoding-decoding 结构中主流的循环神经网络结构(recurrent layers)。不过,这篇文章的细节不是我想要分享的,因为网络上有大堆视频以及博主分享了怎么去读这篇文章。从文章的conclusion上,可以发现作者对他们的工作的热情,这里摘抄几段分享:
In this work, we presented the Transformer, the first sequence transduction model based entirely on attention, replacing the recurrent layers most commonly used in encoder-decoder architectures with multi-headed self-attention.
同时,作者预测了transformer框架不仅对于text有用,而且对images,audio,video领域也会有帮助,可以说是非常有前瞻性了:
We are excited about the future of attention-based models and plan to apply them to other tasks. We plan to extend the Transformer to problems involving input and output modalities other than text and to investigate local, restricted attention mechanisms to efficiently handle large inputs and outputs such as images, audio and video. Making generation less sequential is another research goals of ours.
回归正题,既然是读文章分享,结合我自身经验,有几个点:
- 这篇文章对初读者不算很友好,可以结合网络上的博客和视频去理解这个现在依然非常主流的框架
- 通过这篇文章以及相关的文章,我了解到了encoder-decoder的框架:输入序列 → Encoder → 上下文向量 → Decoder → 输出序列,常用于序列到序列(Seq2Seq)任务,如机器翻译、文本摘要、语音识别等。
- Encoder(编码器):将输入数据(如句子、图像)压缩成一个固定长度的 上下文向量(Context Vector),捕捉其关键信息。
- Decoder(解码器):基于上下文向量,逐步生成输出序列(如翻译后的句子)。
- 接上条,我在自己的工作中虽然算是某种编码解码,但是还是谨慎用encoder-decoder这种词。审稿人给到我的comment本质上是我对主流的工程模型命名不够了解,导致自己陷入坑里。
- 读完这篇文章,不仅让我增加了对文章主要创新点-多头注意力(Multi-Head Attention)的认知,还补充了自然语言处理中Embeddings等知识
- 这篇文章实验部分也很有意思,除了比较分析外,还有很全面的参数分析,以下是文中Table 3:
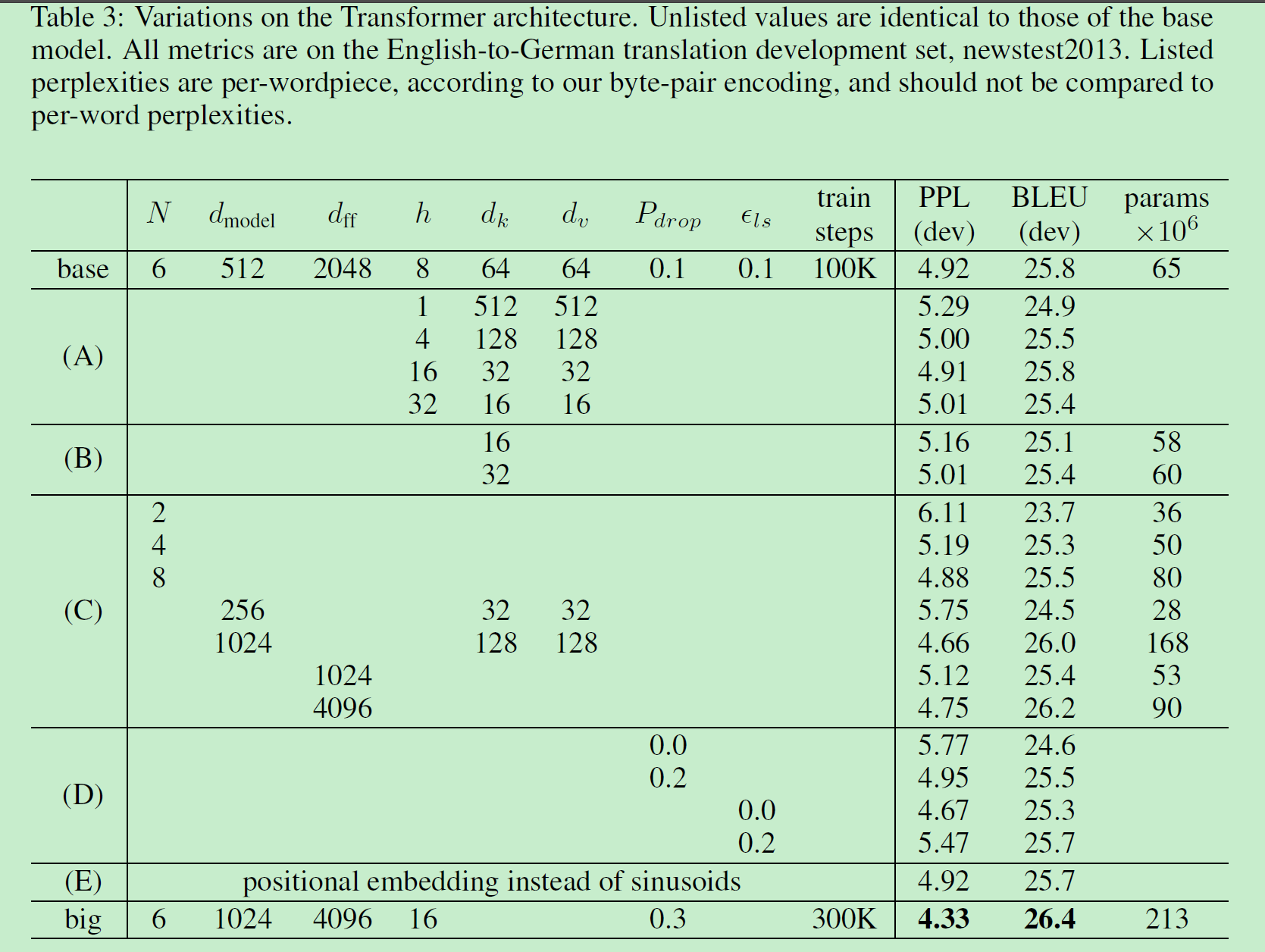
题外话:除了《Attention is All You Need》,江湖上还有篇《Attention is Not All You Need》,同样来自Google公司。或许可以写一篇文章:《Maybe Some Attention is Enough》O(∩_∩)O哈哈~。
此外,我看完文章还有疑惑的点:
- (已解决)为什么encoder部分仅将最后一层用于decoder?
- 有文章探究了其他的连接,产生了corss attention等模型
- 为什么decoder部分
Masked Multi-Head Attention+Add & Norm的后面不接Feed Forward?
欢迎朋友们留言解惑!
Vaswani, Ashish, et al. “Attention is all you need.” Advances in neural information processing systems 30 (2017). ↩︎