MITE-Net: SWaP-Optimized 4K Video Tiny Target Perception for Embodied Edge SAR
Abstract
Real-time tiny target perception in high-resolution imagery is critical for embodied Search-and-Rescue (SAR) missions. However, strict Size, Weight, and Power (SWaP) constraints on edge devices like UAVs create a bottleneck: traditional image downsampling causes severe feature loss, while slice-based processing incurs prohibitive latency. To address this gap, this paper introduces a comprehensive framework encompassing a novel architecture, specialized datasets, and hardware-level benchmarks. First, we propose MITE-Net (Motion-Informed Tiny-target Edge Network), a SWaP-optimized cascaded architecture, which couples a bio-inspired, learning-free Tiny Target Motion-Based Region Proposal Network (TTM-RPN) with a sub-0.14M-parameter R-CNN-like head. Second, to standardize 4K tiny target evaluation, we construct the SAR-Tiny Datasets by relabeling two challenging UAV datasets: SeaDroneSee-Tiny (dynamic maritime scenes, tiny targets predominantly of 64–256 pixels) and UAVID-Tiny (cluttered urban scenes, extremely tiny targets, ≤ 64 pixels). Third, we benchmark against state-of-the-art YOLO models on an edge device, NVIDIA Jetson AGX Xavier, where MITE-Net directly processes 4K maritime imagery, achieving a 100% search success rate at 30.33 FPS. Consuming merely 3.19 W (9.51 FPS/W), MITE-Net vastly outperforms YOLO baselines in target recall and energy efficiency. Conversely, UAVID-Tiny evaluations expose a compound structural limitation: the learning-free bionic front-end struggles against urban backgrounds, while the ultra-lightweight head lacks representational capacity for complex features. Ultimately, this work delivers an efficient onboard perception paradigm and a rigorous baseline guiding future end-to-end SAR architectures.
MITE-Net Architecture
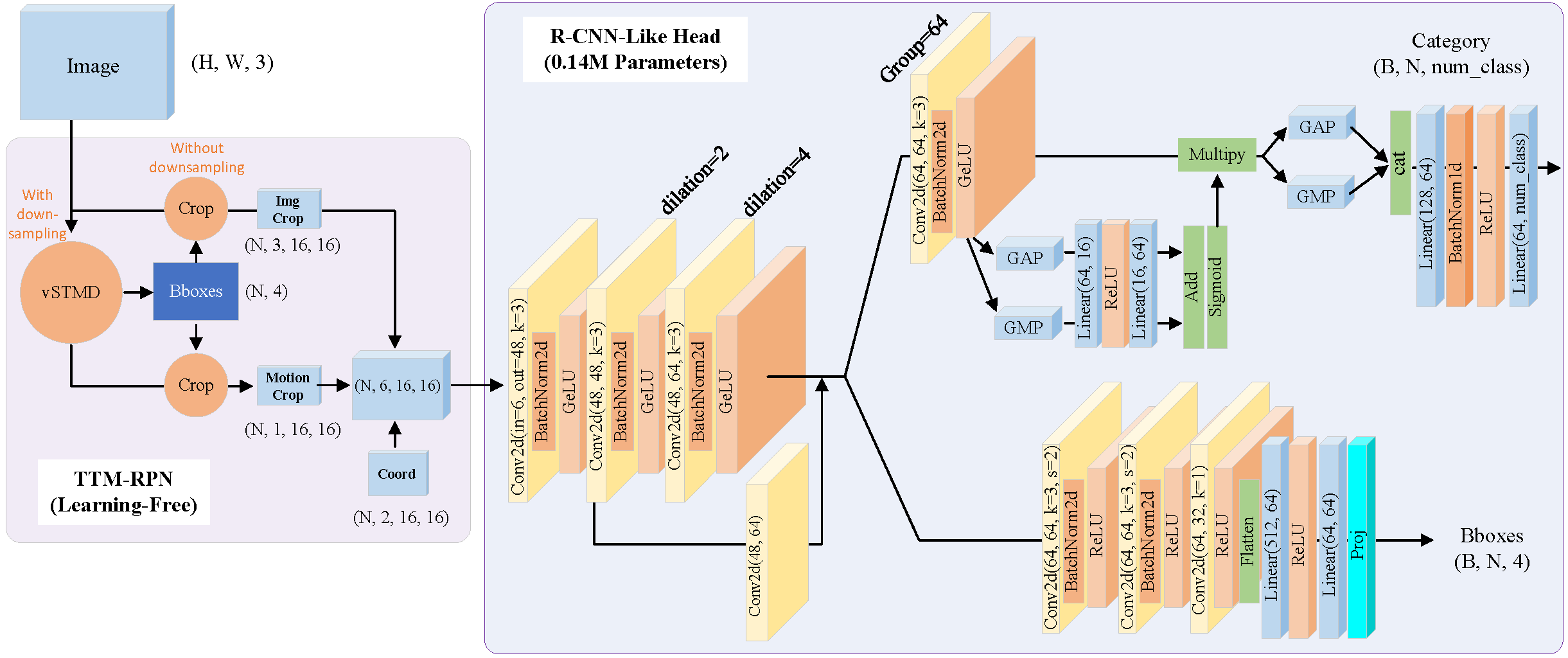
Overall architecture of the proposed MITE-Net. The cascaded framework consists of two stages. Left: A learning-free Bionic-Driven TTM-RPN utilizes vSTMD to extract motion-salient RoIs, which are cropped and concatenated with spatial coordinates into multi-channel inputs. Right: An ultra-lightweight R-CNN-like Head (<0.14M parameters) processes these inputs using dilated and group convolutions, followed by a dual-branch channel attention structure for precise classification and bounding box regression.
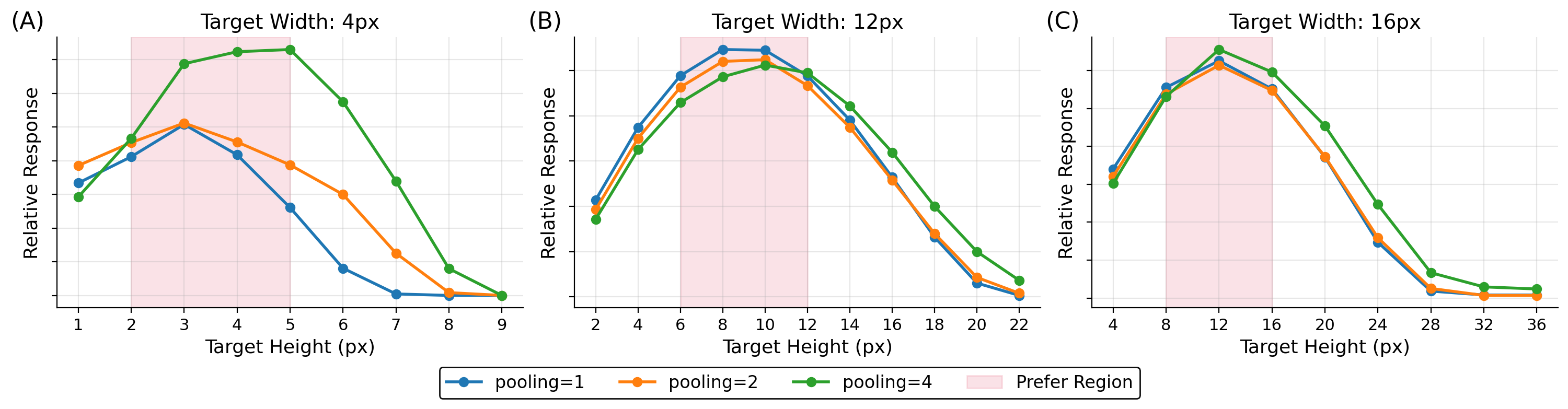
Size selectivity curves of the TTM-RPN for target widths of (A) 4 pixels, (B) 12 pixels, and (C) 16 pixels. By configuring the suppression kernel size to correspond with the input target dimensions, the model consistently achieves its peak relative response when the target height matches the specified target width (pink shaded "Prefer Region"). The qualitative trend remains robust across various pooling parameters (ds ∈ {1, 2, 4}).
SAR-Tiny Datasets
Dataset Statistics
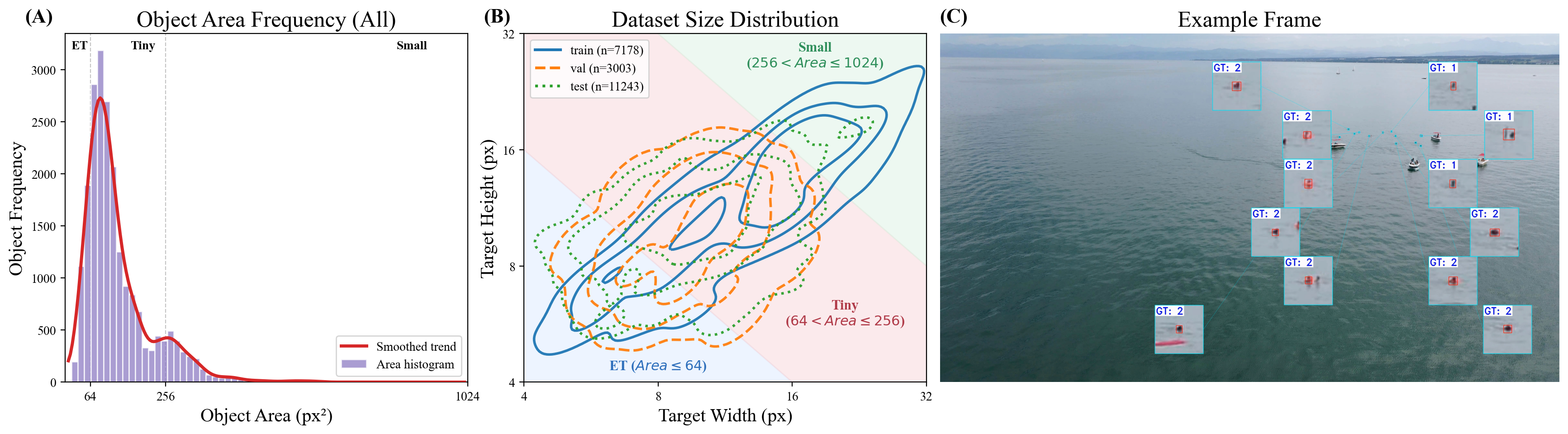
Statistical overview of the curated SeaDroneSee-Tiny dataset. (A) Object area frequency distribution showing a heavily right-skewed trend, where the majority of targets are Extremely Tiny (ET, Area ≤ 64 px²) and Tiny (64 < Area ≤ 256 px²). (B) Joint distribution of target width and height across train/val/test splits, partitioned by three scale regimes. The concentrated test-set contour in the ET and Tiny regions highlights the deliberate "stress test" design. (C) An example frame illustrating detection of multiple scattered targets: GT 1 (swimmer) and GT 2 (swimmer with life jacket).
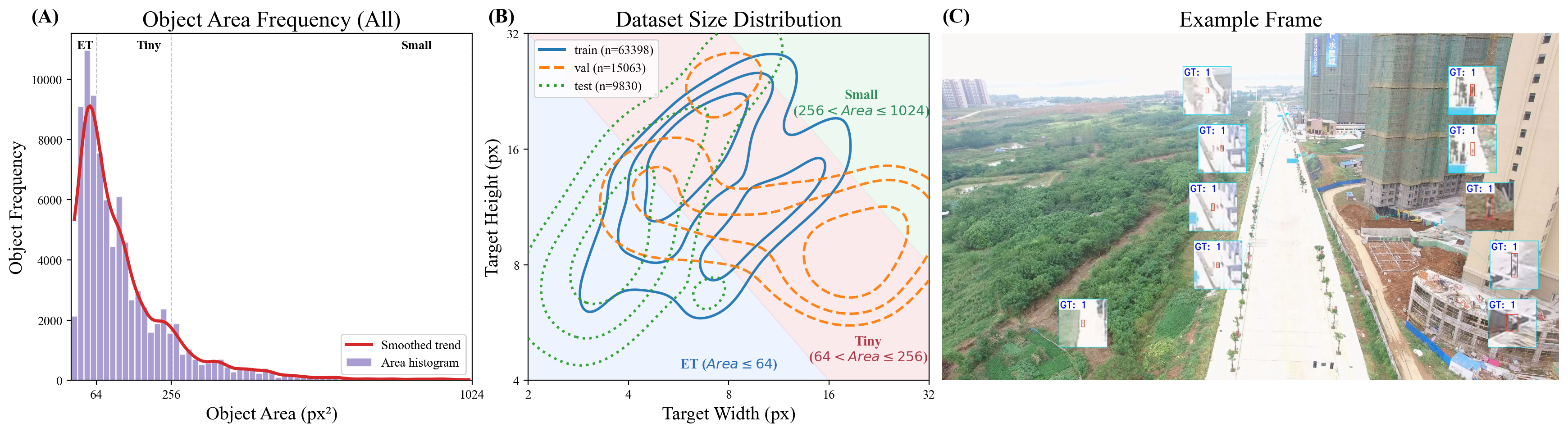
Statistical overview of the curated UAVID-Tiny dataset. (A) Object area frequency distribution with a massive concentration strictly within the Extremely Tiny (ET, Area ≤ 64 px²) region. (B) Joint distribution showing deep penetration into the ET region, underscoring the dataset's complexity. (C) Example test frame of minute targets in cluttered urban background: GT 1 (pedestrians), GT 2 (moving cars), and GT 3 (static cars).
Dataset Summary
| Dataset | Split | Sequences | Frames | BBoxes | Target Density | Key Characteristics |
|---|---|---|---|---|---|---|
| SeaDroneSee-Tiny | Train | seq 2–8 | 3,858 | 7,178 | 1–5 / frame | Dynamic maritime backgrounds. |
| Val | seq 9 | 1,001 | 3,003 | 3 / frame | Baseline maritime background evaluation. | |
| Test | seq 1 | 1,001 | 11,243 | 12 / frame | Density mimicking real-world SAR crises. | |
| UAVID-Tiny | Train | seq 2,5,7,8,16,17,33 | 3,208 | 63,398 | 10–50 / frame | Massive urban clutter. |
| Val | seq 24 | 901 | 15,063 | ~16 / frame | Occlusion and varied lighting conditions. | |
| Test | seq 23 | 701 | 9,839 | ~14 / frame | Early-stage target discovery in urban scenes. |
Experimental Results
SAR Mission-Level Benchmark
| YOLOv11n Resize 1920×1088 |
YOLOv8n-P2 Resize 1920×1088 |
YOLOv8n-P2 (SAHI) 1344×768×9 |
MITE-Net (Ours) Raw 4K + 2ds |
MITE-Net (Ours) Raw 4K + 8ds |
||
|---|---|---|---|---|---|---|
| SeaDroneSee-Tiny | Search Success Rate (%, ↑) | 83.33 | 83.33 | 100 | 100 | 83.33 |
| False Alarm Rate (%, ↓) | 6.83 | 16.77 | 3.12 | 67.72 | 82.29 | |
| Max Search Time (Frame, ↓) | 126 | 74 | 385 | 299 | 119 | |
| Avg. Search Time (Frame, ↓) | 17.90 | 11.20 | 62.58 | 69.00 | 36.80 | |
| UAVID-Tiny | Search Success Rate (%, ↑) | 11.11 | 22.22 | 36.11 | 8.33 | 0.00 |
| False Alarm Rate (%, ↓) | 36.90 | 54.87 | 21.35 | 99.39 | 99.98 | |
| Gray values denote severe algorithmic degradation. MITE-Net excels in maritime SAR (100% SSR) but encounters structural limitations in hyper-cluttered urban scenes. | ||||||
| SWaP | Parameters (M, ↓) | 2.59 | 3.01 | 2.93 | 0.14 | 0.14 |
| Latency (ms, Batch=1, ↓) | 34.31 | 32.03 | 208.68 | 32.97 | 19.11 | |
| Inference Power (W, ↓) | 9.91 | 10.15 | 13.53 | 3.19 | 1.41 | |
| Efficiency (FPS/W, ↑) | 2.94 | 3.08 | 0.35 | 9.51 | 13.54 | |
Inference on NVIDIA Jetson AGX Xavier (Float16). Bold = best, underline = second best.
Qualitative Detection Results
Qualitative demonstration of 4K tiny target perception for the SAR mission using the proposed MITE-Net and baseline models. The top row displays the original 4K resolution images, while the bottom panels show the corresponding zoomed-in regions. Due to the extremely tiny scale of the targets, they appear merely as blurry spots even after significant magnification. The first column shows results on SeaDroneSee-Tiny, where MITE-Net demonstrates excellent detection performance. The second column shows a classification failure case on UAVID-Tiny. The third column shows a bounding box regression failure when detecting multiple tiny objects. Notably, when targets consist of merely a dozen pixels, the recall rate of mainstream YOLO baselines also drops to near zero.
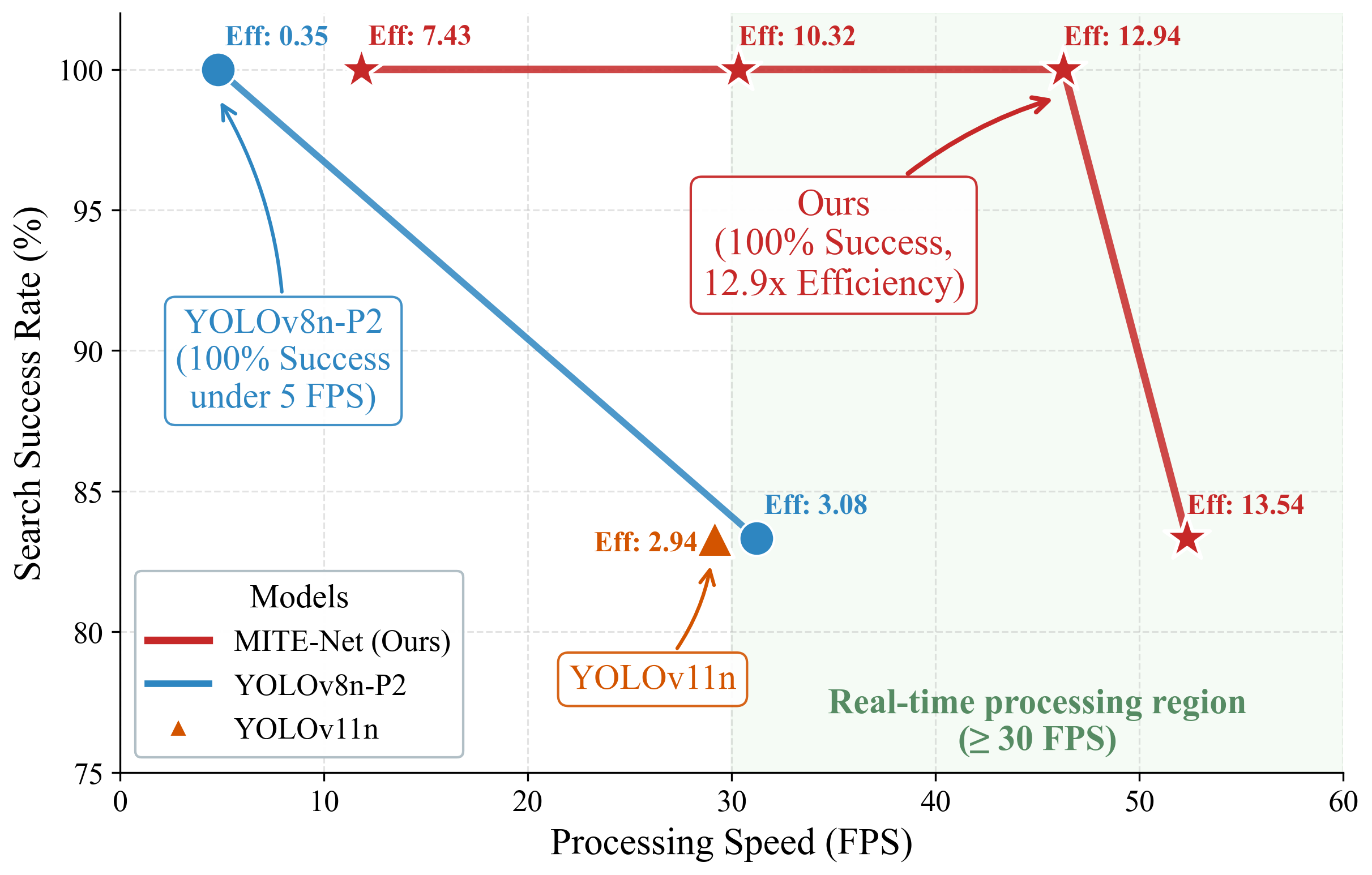
Comparison of search success rate versus processing speed (FPS) among different models. The green shaded area denotes the real-time processing region (≥ 30 FPS), and the annotated numbers indicate the efficiency metric (FPS/W) for each tested configuration. Our proposed MITE-Net achieves an optimal trade-off, maintaining a 100% search success rate within the real-time processing region while demonstrating significantly higher efficiency (12.9×) over the best baseline.
Qualitative Detection Videos
Comparison of MITE-Net with YOLOv11n and YOLOv8n-p2 baselines on both SeaDroneSee-Tiny (maritime) and UAVID-Tiny (urban) test sets. Use the carousel navigation to explore different models and datasets.
SeaDroneSee-Tiny · MITE-Net
SeaDroneSee-Tiny · YOLOv11n
SeaDroneSee-Tiny · YOLOv8n-p2
UAVID-Tiny · MITE-Net
UAVID-Tiny · YOLOv11n
UAVID-Tiny · YOLOv8n-p2
Poster (Generlized by Google NotebookLLM with Gemini)
BibTeX
@article{xu2026mitenet,
title={MITE-Net: SWaP-Optimized 4K Video Tiny Target Perception for Embodied Edge SAR},
author={Xu, Mingshuo and Hua, Mu and Peng, Jigen and Wang, Qi and Yue, Shigang},
journal={arXiv preprint arXiv:},
year={2026}
}