SAR-Tiny Dataset
Two 4K aerial datasets purpose-built for tiny target perception in Search-and-Rescue — spanning dynamic maritime scenes and hyper-cluttered urban landscapes, with rigorous Tiny & Extremely-Tiny (sub-16×16 px) re-annotations.
Overview
Existing UAV datasets are built for other tasks and lack dedicated labels for the minute targets central to Search-and-Rescue. SAR-Tiny addresses this by fully re-annotating two public 4K UAV sources — SeaDroneSee (originally Multi-Object Tracking) and UAVID (originally Semantic Segmentation) — with tight bounding boxes focused on Tiny and Extremely Tiny targets, using CVAT under a strict protocol with multi-stage quality assurance. Targets are graded by pixel size into escalating tiers:
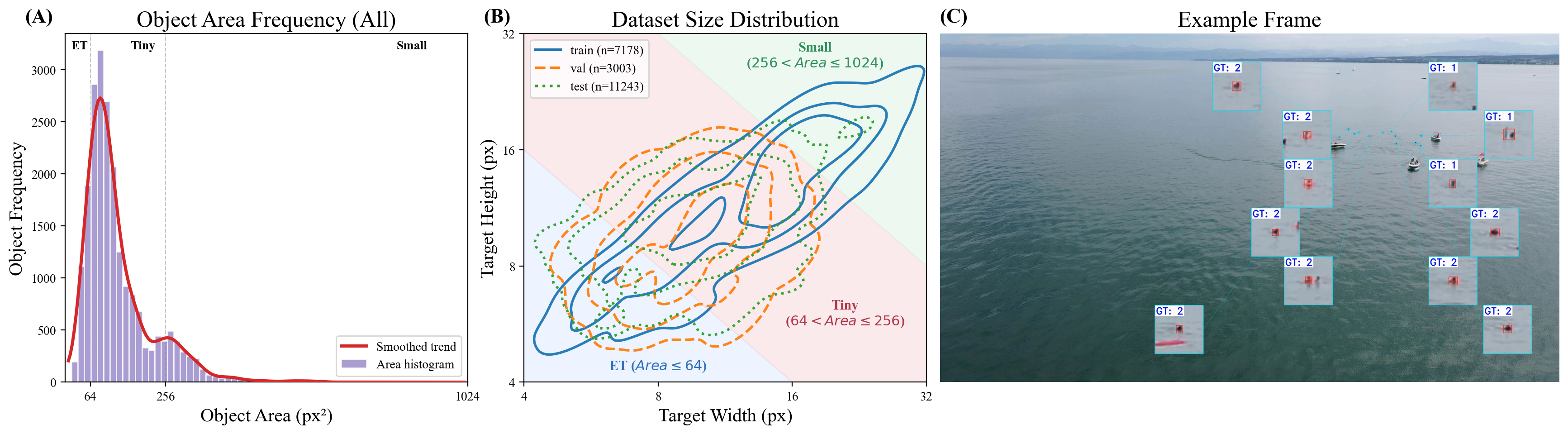
(A) Object-area frequency distribution — heavily right-skewed toward ET and Tiny targets. (B) Joint width–height distribution across splits; the concentrated test contour reflects the deliberate stress-test design. (C) Example frame with multiple scattered targets (GT 1: swimmer; GT 2: swimmer with life jacket).
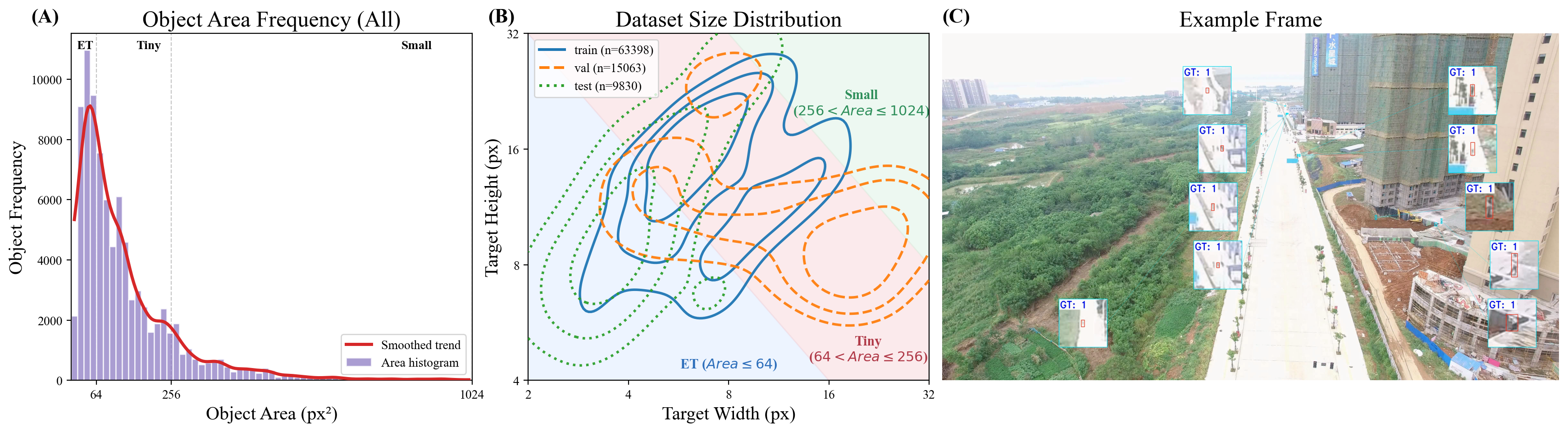
(A) Object-area frequency distribution — a massive concentration strictly within the ET region (≤ 64 px²). (B) Joint width–height distribution showing deep penetration into the ET domain. (C) Example test frame with minute targets in cluttered urban background (GT 1: pedestrians; GT 2: moving cars; GT 3: static cars).
Dataset Summary
| Dataset | Split | Sequences | Frames | BBoxes | Target Density | Key Characteristics |
|---|---|---|---|---|---|---|
| SeaDroneSee-Tiny | Train | seq 2–8 | 3,858 | 7,178 | 1–5 / frame | Dynamic maritime backgrounds. |
| Val | seq 9 | 1,001 | 3,003 | 3 / frame | Baseline maritime background evaluation. | |
| Test | seq 1 | 1,001 | 11,243 | 12 / frame | Density mimicking real-world SAR crises. | |
| UAVID-Tiny | Train | seq 2,5,7,8,16,17,33 | 3,208 | 63,398 | 10–50 / frame | Massive urban clutter. |
| Val | seq 24 | 901 | 15,063 | ~16 / frame | Occlusion and varied lighting conditions. | |
| Test | seq 23 | 701 | 9,839 | ~14 / frame | Early-stage target discovery in urban scenes. |
Data Access
Get the SAR-Tiny annotations
Our re-labeled Tiny / Extremely-Tiny bounding boxes (ground truth) plus the MITE-Net baseline code. The annotations are released under CC BY-NC-SA 4.0 (attribution, non-commercial, share-alike), inherited from the UAVID source license.
Download the original 4K imagery
Obtain the raw videos/images from the source datasets below, then align them with our annotations.
Maritime UAV footage. SeaDroneSee-Tiny is re-labeled from the MOT subset.
Urban UAV video. UAVID-Tiny is re-labeled with tiny-target bounding boxes.
Citation
If you use the SAR-Tiny datasets, please cite our work:
@article{xu2026mitenet,
title={MITE-Net: SWaP-Optimized 4K Video Tiny Target Perception for Embodied Edge SAR},
author={Xu, Mingshuo and Hua, Mu and Peng, Jigen and Wang, Qi and Yue, Shigang},
journal={arXiv preprint arXiv:},
year={2026}
}Please also cite the source datasets
SAR-Tiny re-labels imagery from SeaDronesSee and UAVID. You must cite the original works and comply with their licenses.
@article{LYU2020108,
author = {Ye Lyu and George Vosselman and Gui-Song Xia and Alper Yilmaz and Michael Ying Yang},
title = {UAVid: A semantic segmentation dataset for UAV imagery},
journal = {ISPRS Journal of Photogrammetry and Remote Sensing},
volume = {165},
pages = {108--119},
year = {2020},
issn = {0924-2716},
doi = {https://doi.org/10.1016/j.isprsjprs.2020.05.009},
url = {http://www.sciencedirect.com/science/article/pii/S0924271620301295}
}@article{kiefer20221st,
title={1st Workshop on Maritime Computer Vision (MaCVi) 2023: Challenge Results},
author={Kiefer, Benjamin and Kristan, Matej and Per{\v{s}}, Janez and {\v{Z}}ust, Lojze
and Poiesi, Fabio and Andrade, Fabio Augusto de Alcantara and Bernardino, Alexandre
and Dawkins, Matthew and Raitoharju, Jenni and Quan, Yitong and others},
journal={arXiv preprint arXiv:2211.13508},
year={2022}
}
@inproceedings{varga2022seadronessee,
title={SeaDronesSee: A maritime benchmark for detecting humans in open water},
author={Varga, Leon Amadeus and Kiefer, Benjamin and Messmer, Martin and Zell, Andreas},
booktitle={Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision},
pages={2260--2270},
year={2022}
}